
Agent Observability Powers Agent Evaluation
LangChain has published a detailed analysis explaining how observability serves as the foundation for reliable evaluation of AI agents, addressing the unique challenges that arise when debugging and improving non-deterministic systems.
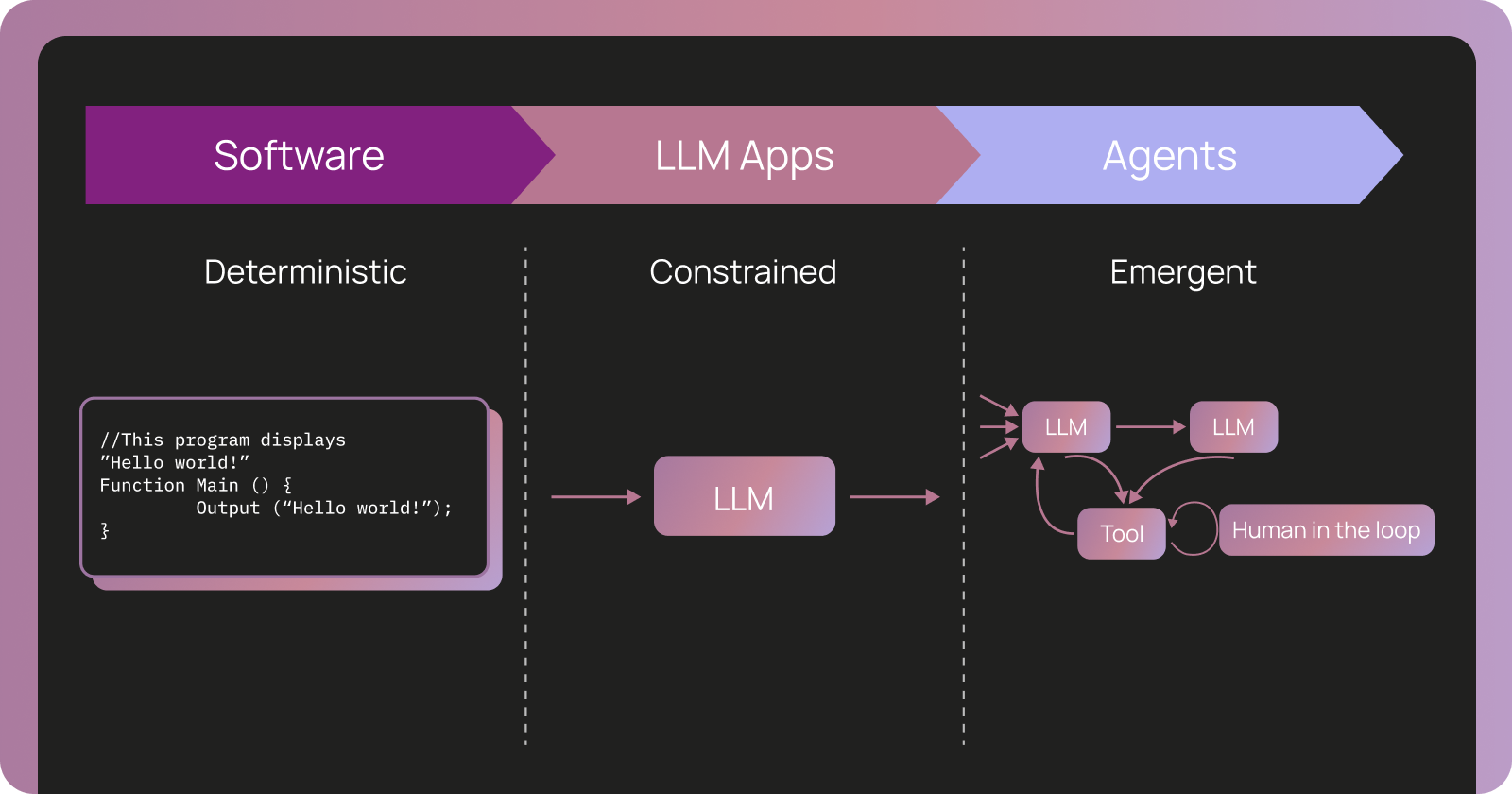
In a new blog post, LangChain argues that traditional software debugging approaches fall short for AI agents. While conventional applications produce predictable errors with clear stack traces, agents operate through complex, open-ended reasoning chains that require deep visibility into their internal decision-making processes. The company positions observability not just as a monitoring tool but as the core mechanism that enables systematic evaluation and continuous improvement of agent performance.
"You can't build reliable agents without understanding how they reason, and you can't validate improvements without systematic evaluation," the LangChain team writes in the announcement. This principle forms the foundation of their latest insights into agent development workflows.
The Fundamental Differences in Agent Debugging
The LangChain blog post highlights several critical distinctions between traditional software observability and what is required for AI agents. Unlike deterministic code where failures can be traced to specific lines, agents generate behavior through dynamic interactions between large language models, tools, memory systems, and external data sources.
Agent observability, as defined across the industry, refers to the ability to explain why an agent behaved a certain way by inspecting the internal steps and context that drove the outcome. It answers fundamental questions such as: What did the agent see? What options did it consider? Why did it choose a particular action?
According to LangChain, traces — detailed records of an agent's complete execution path — document exactly where agent behavior emerges. These traces capture not only inputs and outputs but also the reasoning steps, tool calls, intermediate thoughts, and contextual information that influenced each decision.
This level of granularity becomes essential because agents often tackle complex, open-ended tasks. Evaluating them differs significantly from evaluating traditional software, where unit tests and predefined test cases can reliably verify correctness. Agent evaluation must account for multiple valid approaches to the same problem, varying levels of efficiency, and the potential for creative but sometimes unpredictable solutions.
How Traces Enable Multi-Faceted Evaluation
The core argument from LangChain centers on the powerful connection between observability data and evaluation capabilities. Traces serve as rich datasets that power evaluation in numerous ways:
- Performance Analysis: By examining trace data, developers can identify patterns in successful versus unsuccessful agent runs, pinpointing where reasoning breaks down or where inefficient tool usage occurs.
- Regression Testing: Detailed traces allow teams to compare agent behavior before and after changes, ensuring improvements in one area do not introduce regressions elsewhere.
- Benchmark Development: The structured data within traces helps create more sophisticated evaluation benchmarks that go beyond simple success/fail metrics.
- Root Cause Analysis: When agents produce unexpected or incorrect outputs, traces provide the complete context needed to understand the reasoning path that led to the failure.
This approach aligns with broader industry thinking. As noted in related discussions from IBM and Hugging Face, observability enables organizations to evaluate agent performance by collecting data about actions, decisions, and resource usage. Online evaluation, which monitors agents during real user interactions, becomes possible when comprehensive trace data is available.
Technical Context and Industry Landscape
LangChain's focus on agent observability comes at a pivotal time in the AI agent space. As organizations move beyond simple chatbots toward autonomous agents capable of multi-step planning and tool usage, the need for robust debugging and evaluation infrastructure has grown significantly.
The company, known for its popular open-source framework for building LLM-powered applications, has increasingly emphasized production readiness. Their LangSmith platform, which provides observability and evaluation tools, directly embodies the principles outlined in the blog post.
This emphasis on observability also reflects emerging standards in the field. The OpenTelemetry project has highlighted the importance of establishing common formats for agent telemetry to prevent vendor lock-in and enable interoperability between different observability and evaluation tools.
Industry experts increasingly recognize that because of agents' non-deterministic nature, telemetry data serves as a critical feedback loop. This data can be used to continuously learn from and improve agent quality by feeding into evaluation systems and fine-tuning processes.
Impact on Developers and the AI Industry
For developers building with LangChain and similar frameworks, this focus on observability-first development represents a significant shift in methodology. Rather than treating observability as an afterthought, teams are encouraged to design their agent architectures with comprehensive tracing from the beginning.
This approach promises several benefits:
- Faster Debugging Cycles: Developers can quickly understand why agents fail rather than spending hours attempting to reproduce complex reasoning paths.
- More Reliable Agents: Systematic evaluation based on real trace data leads to measurable improvements in agent reliability and performance.
- Better Collaboration: Detailed traces provide a common language for discussing agent behavior between engineers, product managers, and domain experts.
- Scalable Evaluation: Organizations can move from manual spot-checking to automated, data-driven evaluation systems.
The implications extend beyond individual development teams. As AI agents become more prevalent in enterprise applications, the ability to demonstrate reliability, explainability, and continuous improvement will become key requirements for adoption. Observability infrastructure may emerge as a competitive differentiator among agent frameworks and platforms.
What's Next for Agent Observability
LangChain's analysis suggests that the field will continue evolving toward more sophisticated observability and evaluation capabilities. Future developments may include standardized trace formats, more advanced analytics built on trace data, and tighter integration between observability platforms and agent development workflows.
The company indicates that understanding these principles is essential for anyone building production-grade AI agents. As the technology matures, systematic observability and evaluation will likely become table stakes rather than advanced features.
Industry-wide efforts around standards, as discussed by the OpenTelemetry community, point toward greater interoperability between different tools and frameworks. This could ultimately benefit developers by reducing the complexity of managing observability across multi-vendor agent stacks.
For organizations just beginning their agent journey, LangChain recommends prioritizing observability infrastructure early in the development process. The investment in comprehensive tracing and evaluation capabilities pays dividends as agents grow more complex and are deployed in higher-stakes environments.
The blog post serves as both a technical deep dive and a call to action for the AI engineering community to treat agent observability as a foundational requirement rather than an optional enhancement.
Sources
- Agent Observability Powers Agent Evaluation
- The Complete Guide to AI Agent Observability and Monitoring - StackAI
- Why observability is essential for AI agents | IBM
- AI Agent Observability and Evaluation - Hugging Face Agents Course
- AI Agent Observability - Evolving Standards and Best Practices | OpenTelemetry