
The short version
Databricks Vector Search is a tool by Databricks that helps AI apps quickly find similar items in huge collections of data points called "vectors" – think of it like super-powered search for pictures, recommendations, or chatbots that pull real info. Their new "Storage Optimized" version breaks apart the storage and processing so it can handle billions of these vectors at a fraction of the cost of older systems, with indexes built in under 8 hours, 20x faster creation, and up to 7x lower running costs. For everyday people, this means cheaper, smarter AI in apps like Netflix suggestions or Google image search, without your phone or subscription prices spiking as AI gets bigger.
What happened
Imagine you're running a massive online store with photos of every product ever sold – millions, then billions. Old AI search tools for this (called vector search) keep everything in super-fast but pricey computer memory, like stuffing your entire photo album into a fancy speed-reader that costs a fortune per page. When the album hits billions of pics, costs explode because you need way more memory and machines, and adding new pics slows down searches.
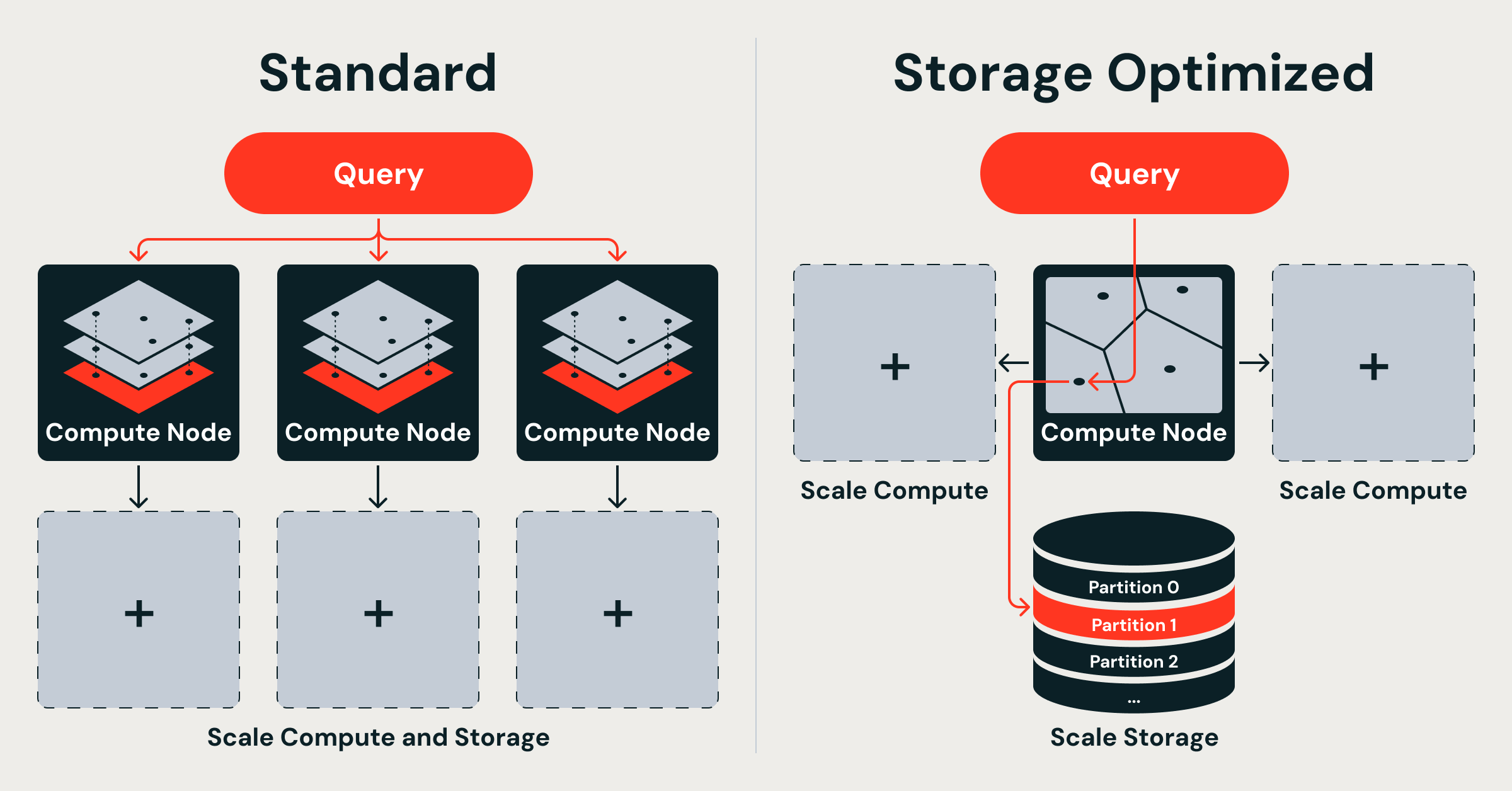
Databricks hit this wall with their original Vector Search and redesigned it from the ground up. They unveiled "Storage Optimized endpoints" alongside their existing "Standard endpoints." Standard ones keep full-detail vectors in memory for lightning-fast searches (tens of milliseconds – quicker than a blink). The new optimized version "decouples" things: cheap cloud storage holds the vectors and indexes (like a big, affordable warehouse), while short-lived processing clusters build them separately using Spark (their data-crunching engine). Queries run on a custom Rust engine with separate "thread pools" – one for grabbing data, one for math-heavy similarity checks – so nothing gets stuck waiting.
Key engineering wins:
- Separate storage from compute: Indexes live in cheap object storage, loaded only when needed. No more tying expensive memory to data ownership.
- Distributed indexing on Spark: They built clustering, compression, and smart data layout as scalable Spark jobs – linear scaling means double the computers, double the speed.
- Rust query engine: Dual-runtime setup prevents I/O (data fetching) from hogging CPU for vector math.
Benchmarks from Databricks: Billion-vector indexes built in under 8 hours (20x faster than before), and serving costs up to 7x lower. Latency is hundreds of milliseconds (still fast for most apps, like a quick web page load), trading a bit of speed for huge scale and savings. This powers AI staples like in-app search, recommendations, entity matching (linking "John Smith" across records), and RAG (chatbots fetching real docs before answering).
It's not a tweak – they ditched single-machine limits for a three-layer setup: storage in cloud blobs, ingestion on temporary Spark clusters (fully isolated from queries), and stateless query nodes. No more "tight coupling" where updates clog searches or scaling means copying everything everywhere.
Why should you care?
Vector search is the invisible engine behind AI you use daily. It's why Netflix nails your next binge-watch, why Google Lens finds matching outfits from a photo, why chatbots like me give accurate answers instead of hallucinations, and why fraud detection spots weird charges instantly. As datasets balloon to billions (think all TikTok videos or every customer review ever), old systems get too expensive – companies pass that cost to you via higher prices or slower apps.
Databricks' fix slashes those costs dramatically. For you: AI gets "smarter" at scale without price hikes. Apps stay fast even with zillions of data points. Your recommendations get eerily accurate (matching your weird tastes perfectly), searches pull deeper insights, and AI tools like personalized health apps or job matchers handle real-world messiness better. In a world racing to AI-ify everything, this keeps innovation affordable – no more "AI tax" on your streaming sub or phone bill.
Competitive context matters too: Others are chasing billion-scale too. AWS just launched GPU-boosted vector search on OpenSearch, claiming billion-scale indexes in under an hour at 1/4 cost and 10x faster indexing (but GPUs cost 1.5x more). VectorChord hits 1 billion on PostgreSQL, ScyllaDB boasts "monstrous speed," and research like GustANN pushes single-GPU high-throughput. OpenSearch highlights "decoupled design" flexibility for future tech. Databricks stands out with Spark-native scaling, 20x indexing speed, 7x cost cuts, and Rust efficiency – no GPUs needed, pure software smarts for cloud economics.
What changes for you
Practically, nothing disrupts your day – this is backend plumbing for developers building AI apps. But ripples hit fast:
- Cheaper AI apps: Services using Databricks (many enterprises do) save 7x on vector serving, so your SaaS tools (like customer support bots or e-commerce) cost less to run. Expect stable or dropping prices for AI features.
- Bigger, better AI: Billions of vectors mean richer training data. Your Spotify playlist? Scans billions of listens for perfect matches. Photo apps? Find dupes across global libraries.
- Faster everything at scale: No more "ingestion stalls" – apps update live without lag. ChatGPT-like tools with RAG stay accurate on massive knowledge bases.
- Deployment picks: Devs choose Standard for speed-critical (e.g., real-time gaming AI) or Storage Optimized for cost/scale (e.g., recommendation engines). You get the best of both indirectly.
- No app changes needed: Works seamlessly with existing Databricks setups. If your company uses it, internal AI gets turbo-boosted.
Long-term: Democratizes billion-scale AI. Small startups rival giants without bankrupting on memory. You benefit from innovative apps – think hyper-personalized news feeds or AR try-ons scanning billions of real outfits.
Frequently Asked Questions
### What exactly is vector search, and why is it a big deal for AI?
Vector search finds "similar" items in huge lists by turning data (images, text, audio) into math points (vectors) and measuring closeness – like plotting friends on a map and finding nearest neighbors. It's crucial for AI because it powers recommendations (your YouTube next-video), semantic search (finding "best running shoes" without exact words), and RAG (AI pulling facts before replying). At billions of vectors, it breaks old systems – Databricks fixed that for cheaper, scalable AI you use daily.
### How much cheaper and faster is Databricks' new version?
They claim 20x faster indexing (billion vectors in <8 hours vs. old methods), up to 7x lower serving costs, thanks to decoupling storage/compute. Latency: Standard is tens of ms (ultra-fast), Optimized is hundreds of ms (still snappy for most). Memory savings are massive – e.g., 100M 768-dim vectors eat 286 GiB RAM alone before indexes; billions would bankrupt you. No pricing details given, but "fraction of the cost" via cheap object storage.
### Is this free for regular users, or just for big companies?
Databricks is enterprise-focused (think businesses paying for cloud data platforms), so no free tier here – but it's infrastructure for apps you use. Indirectly free/cheap for you: Companies save money, so consumer AI (Netflix, Google) doesn't raise prices. Devs pay Databricks bills, but 7x savings trickle down.
### How does it compare to AWS, Google, or others?
Databricks emphasizes software decoupling on Spark/Rust (no pricey GPUs), hitting 20x indexing/7x cost wins. AWS OpenSearch GPUs build billions in <1 hour at 1/4 cost/10x speed but higher instance prices. ScyllaDB claims fastest benchmarks; VectorChord scales Postgres to 1B; GustANN does high-throughput on one GPU. All chase billion-scale, but Databricks shines for Spark users with linear scaling and isolation.
### When can I try this, and will it affect my apps?
Available now as "Storage Optimized endpoints" in Databricks Vector Search. No direct consumer access – it's for devs building AI on Databricks. You'll notice via better apps soon: Faster recommendations, smarter searches in tools from companies using it (e.g., retail, media). No changes to your phone/apps needed.
The bottom line
Databricks just solved a massive pain point in AI infrastructure: scaling vector search to billions of data points without exploding costs or slowing down. By smartly splitting storage, building, and querying – using cheap cloud storage, scalable Spark jobs, and an efficient Rust engine – they deliver 20x faster indexing in under 8 hours and 7x cheaper serving for workloads where scale trumps split-second speed. For you, the non-tech user, this means the AI magic in your daily life (spot-on recommendations, accurate chatbots, instant similar-image finds) gets way more powerful and affordable as data explodes. No price hikes, no slowdowns – just better apps quietly powered by this breakthrough. In the AI arms race, innovations like this keep your experience improving without you lifting a finger.
Sources
- Databricks Blog: Decoupled by Design: Billion-Scale Vector Search
- AWS Blog: Build billion-scale vector databases in under an hour with GPU acceleration on Amazon OpenSearch Service
- ACM: High-Throughput, Cost-Effective Billion-Scale Vector Search with a Single GPU
- VectorChord Blog: Scaling Vector Search to 1 Billion on PostgreSQL
- OpenSearch Blog: GPU-accelerated vector search in OpenSearch: A new frontier
- StorageNewsletter: ScyllaDB Brings Massive-Scale Vector Search to Real-Time AI
(Word count: 1247)