
Decoupled by Design: Billion-Scale Vector Search: A Technical Deep Dive
Executive summary
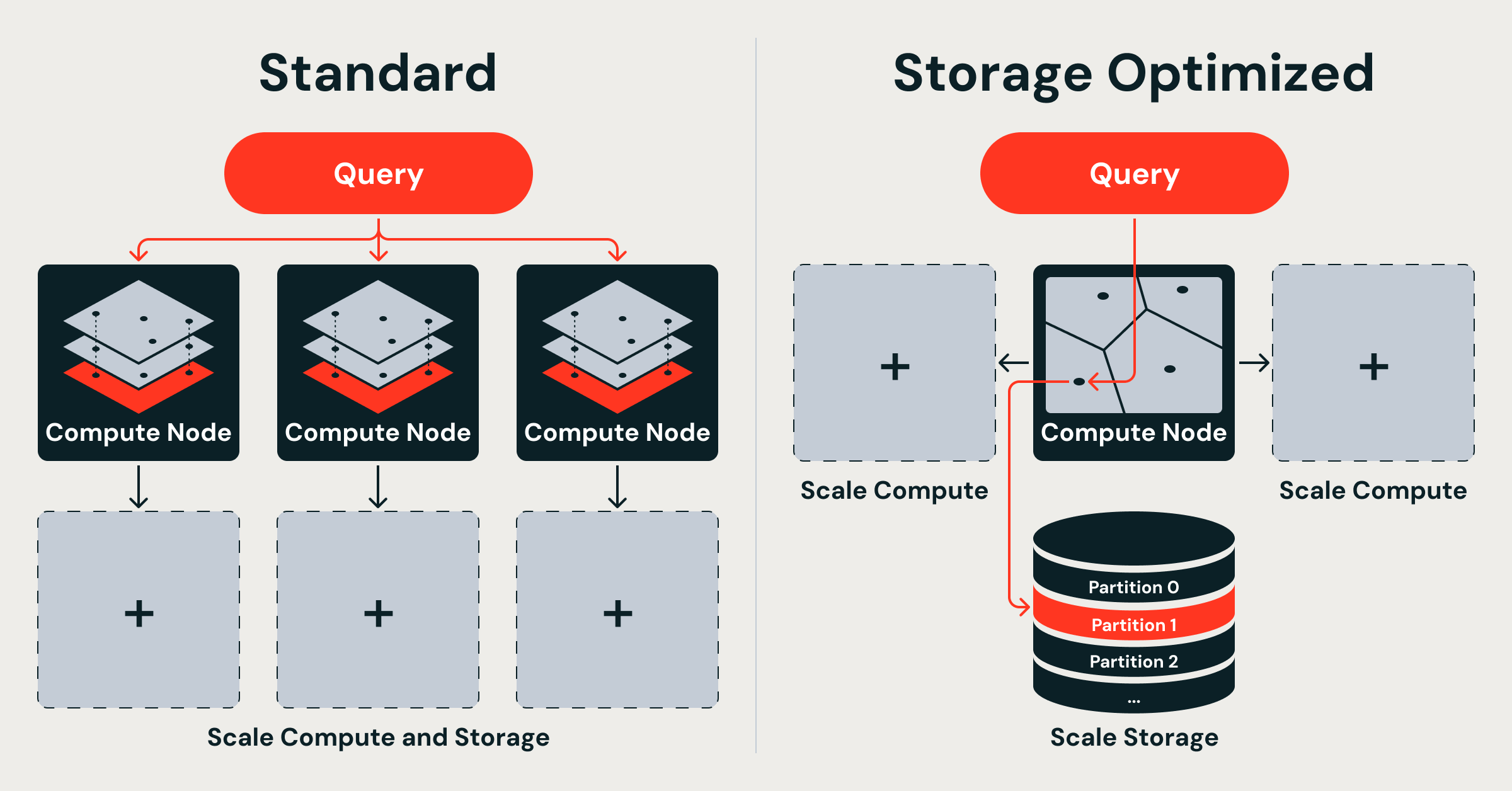
- Databricks Vector Search introduces Storage Optimized endpoints that fully decouple storage, indexing, and serving by placing vector indexes in cloud object storage and using stateless query nodes, enabling billion-scale indexes at up to 7× lower serving cost than tightly-coupled in-memory designs.
- The system builds indexes using custom distributed Spark-native algorithms (clustering, vector compression, partition-aligned layout) on ephemeral serverless clusters, achieving billion-vector index construction in under 8 hours and 20× faster indexing compared to prior approaches.
- Queries are served by a purpose-built Rust engine with a dual-runtime architecture that separates async I/O and CPU-bound similarity search, delivering hundreds-of-milliseconds latency as a deliberate trade-off for cost and scale.
- Two deployment options now coexist: Standard (in-memory HNSW, tens-of-ms latency) and Storage Optimized (object-storage backed, sub-second latency), giving developers an explicit latency-vs-cost knob for RAG, recommendation, and entity-resolution workloads.
Technical architecture
Traditional vector databases, including Databricks’ original Standard Vector Search, follow a shared-nothing architecture derived from distributed text search. Each node is assigned a random shard of the dataset and maintains a complete, memory-resident HNSW graph over full-precision vectors. While HNSW provides excellent recall and low tail latency, the design tightly couples three resources: storage, index, and serving compute. Because both the raw vectors and the HNSW graph must reside in RAM, scaling from hundreds of millions to billions of vectors forces linear growth in memory footprint and node count. At 768 dimensions with float32, 100 M vectors already require ~286 GiB just for the raw data; a billion vectors push the requirement into multiple terabytes before index overhead. Random sharding further exacerbates the problem: every query fans out to all shards, incurring network and CPU overhead proportional to the number of nodes.
Databricks Storage Optimized Vector Search discards this coupling. The new architecture rests on three explicit design decisions:
-
Storage-compute separation
All vector data and indexes live durably in cloud object storage (Delta Lake). Query nodes are stateless; they load only the portions of the index required for a given request into memory. This eliminates the need to replicate the entire dataset across every serving node and allows storage to scale independently of compute. -
Ingestion decoupled from serving
Index construction and maintenance run on ephemeral, serverless Spark clusters that are completely isolated from the query path. Because ingestion never contends for the same CPU or memory used by live queries, the system can sustain high ingest rates without degrading p99 latency. After an index is built, the resulting artifacts (compressed vectors, partition metadata, and graph segments) are written back to object storage. Subsequent updates trigger incremental Spark jobs that produce new immutable index versions, enabling safe, zero-downtime refresh. -
Distributed indexing algorithms built natively on Spark
Rather than delegating indexing to single-machine libraries (FAISS, HNSWlib, etc.), Databricks implemented its own distributed pipeline:- Distributed clustering partitions the vector space into coarse buckets that align with Delta Lake partitioning. This locality-aware layout dramatically reduces the number of partitions a typical query must touch.
- Vector compression applies product quantization (PQ) and other lossy techniques inside Spark executors, shrinking memory and I/O footprints.
- Partition-aligned data layout ensures that each Spark partition maps to a self-contained searchable unit, enabling efficient pruning and parallel execution.
The resulting index is not a single monolithic HNSW graph but a hierarchy of quantized, partitioned indexes that can be loaded on demand.
Query serving engine
Queries are executed by a purpose-built Rust engine running inside the query nodes. The engine employs a dual-runtime architecture:
- One thread pool is dedicated to asynchronous I/O (reading index segments from object storage, prefetching, caching).
- A separate thread pool handles CPU-intensive vector distance computations and graph traversal.
By isolating these workloads, the engine prevents I/O stalls from starving compute resources and vice versa. The Rust implementation also enables fine-grained control over SIMD intrinsics, memory layout, and cache behavior, contributing to the observed sub-second latencies even when only a fraction of the index is resident in RAM.
Performance analysis
Databricks reports the following headline metrics for Storage Optimized endpoints on internal production workloads:
- Billion-vector indexes built in under 8 hours.
- Indexing throughput 20× faster than the previous tightly-coupled implementation.
- Serving cost up to 7× lower than Standard endpoints for equivalent scale.
- Query latency in the hundreds of milliseconds (typical p50 ~200–400 ms depending on index size, dimensionality, and recall target).
While exact public benchmarks with standardized datasets (e.g., billion-scale Deep1B, LAION, or MS MARCO) are not disclosed in the announcement, the architectural trade-offs are clear. Standard endpoints continue to offer low tens-of-milliseconds latency at higher cost, while Storage Optimized endpoints sacrifice single-digit millisecond response times for massive cost and scale advantages.
Competitive context (derived from contemporaneous announcements):
- AWS OpenSearch recently added GPU-accelerated k-NN indexing claiming billion-scale indexes in under an hour and up to 10× faster indexing at ~25 % of previous cost.
- Academic systems such as GustANN demonstrate GPU-centric, CPU-assisted billion-scale graph ANNS on a single GPU.
- ScyllaDB, VectorChord (PostgreSQL), and others are also targeting large-scale vector workloads with different cost/latency profiles.
Databricks’ approach is distinguished by its deep integration with Spark and Delta Lake, serverless ingestion, and the explicit dual-endpoint model that lets the same logical index be served in either mode.
Technical implications
For the Databricks ecosystem the launch has several immediate consequences:
- Mosaic AI and Unity Catalog users can now index embeddings generated by Foundation Model APIs or custom models at virtually unlimited scale without provisioning massive memory-optimized clusters.
- Retrieval-augmented generation (RAG) applications that previously hit cost or scale ceilings can move from prototype to production using Storage Optimized endpoints, accepting sub-second latency for knowledge-base sizes measured in billions of chunks.
- Data engineering teams benefit from Spark-native indexing: the same cluster that performs ETL can now also build vector indexes, reducing operational complexity and data movement.
- Cost accounting becomes more predictable; storage is paid at object-storage rates while compute is provisioned only for query traffic, aligning with modern serverless usage patterns.
The design also paves the way for future hardware acceleration. Because index artifacts live in object storage, Databricks can introduce GPU-based or FPGA-based query nodes that load the same compressed partitions without changing upstream indexing pipelines.
Limitations and trade-offs
The Storage Optimized design is not a universal replacement:
- Latency is intentionally higher. Workloads requiring <50 ms p95 response (real-time product search, low-latency chat) will continue to use Standard endpoints.
- Freshness is bounded by the frequency of Spark-based index rebuilds. While incremental updates are supported, the architecture favors periodic versioning over fully transactional, sub-second index updates.
- Recall/quality may be slightly lower than pure in-memory HNSW due to quantization and coarse partitioning, although the announcement claims production-grade quality is maintained through careful tuning of PQ parameters and hybrid coarse-to-fine search.
- Debugging and observability are more complex; engineers must reason about both Spark job performance (index build) and Rust query-engine metrics (serving).
Expert perspective
From an architectural standpoint, Databricks has executed a textbook “decoupled by design” refactor that mirrors the evolution of data warehouses (from monolithic to lakehouse) and compute engines (from always-on clusters to serverless). By treating vector indexes as immutable artifacts in object storage and leveraging Spark’s mature distributed execution model, the team avoided the trap of trying to incrementally optimize a fundamentally coupled system. The dual-runtime Rust engine demonstrates thoughtful systems engineering to squeeze maximum performance from commodity hardware while keeping the control plane simple.
The most significant contribution may be the explicit latency-vs-cost slider. Rather than promising “low latency at any scale,” Databricks acknowledges that different AI workloads have different requirements and gives practitioners a concrete architectural choice. This honesty, combined with the 7× cost reduction at billion scale, positions Databricks Vector Search as a serious contender for production RAG and recommendation systems where total cost of ownership matters more than raw QPS.
Technical FAQ
### How does Storage Optimized Vector Search compare to Standard endpoints on latency and cost?
Standard endpoints keep full-precision vectors and HNSW graphs in memory, delivering tens-of-milliseconds p50 latency but at significantly higher RAM cost. Storage Optimized endpoints use object storage + on-demand loading, trading latency (hundreds of ms) for up to 7× lower serving cost and linear scalability to billions of vectors.
### What is the indexing pipeline and how long does it take for a billion vectors?
Indexing is performed as distributed Spark jobs using custom clustering, product quantization, and partition-aligned layout. Databricks reports complete billion-vector indexes in under 8 hours on appropriately sized serverless clusters—approximately 20× faster than the previous in-process indexing approach.
### Is the new system backwards-compatible with existing Vector Search indexes and APIs?
Yes. The same Vector Search API and index management surface is used; users simply choose the endpoint type (Standard vs. Storage Optimized) at index creation or via endpoint configuration. Existing Standard indexes continue to operate unchanged.
### Can the Storage Optimized indexes take advantage of GPU acceleration in the future?
The architecture is explicitly designed for it. Because indexes live in object storage as compressed, partitioned artifacts, Databricks can introduce GPU-equipped query nodes that load the same data without requiring re-indexing. No timeline is given, but the decoupled design makes hardware evolution straightforward.
Sources
- Databricks Blog – Decoupled by Design: Billion-Scale Vector Search
- AWS Blog – GPU-accelerated vector indexing on Amazon OpenSearch Service
- ACM SIGMOD – GustANN: High-Throughput, Cost-Effective Billion-Scale Vector Search with a Single GPU
- Additional competitive context from VectorChord, ScyllaDB, and OpenSearch announcements (2024–2025).